Applying Over-Sampling Methods to Highly Imbalanced Data

I mentioned various undersampling approaches for dealing with highly imbalanced data in the earlier post “Applying Under-Sampling Methods to Highly Imbalanced Data” In this article, I present oversampling strategies for dealing with the same problem.
By reproducing minority class examples, oversampling raises the weight of the minority class. Although it does not provide information, it introduces the issue of over-fitting, which causes the model to be overly specific. It is possible that while the accuracy for the training set is great, the performance for unseen datasets is poor.
Oversampling Methods
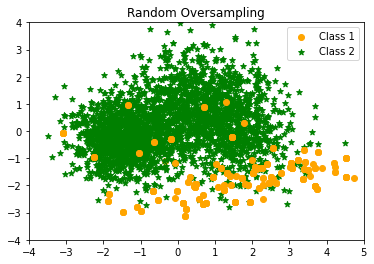
- Random Oversampling of the minority class
Random oversampling just replicates the minority class instances at random. Overfitting is thought to be more likely when random oversampling is used. Random undersampling, on the other hand, has the main disadvantage of discarding useful data.
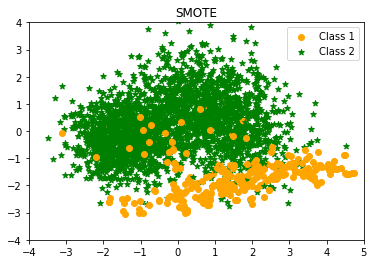
- Synthetic Minority Oversampling Technique (SMOTE)
Chawla et al. (2002) present the Synthetic Minority Over-sampling Technique to avoid the over-fitting problem (SMOTE). This approach, which is regarded state-of-the-art, is effective in many different applications. Based on feature space similarities between existing minority occurrences, this approach produces synthetic data. To generate a synthetic instance, it locates the K-nearest neighbours of each minority instance, chooses one at random, and then performs linear interpolations to generate a new minority instance in the neighbourhood.
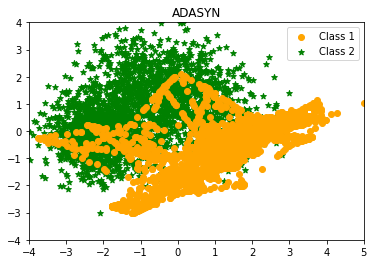
- ADASYN: Adaptive Synthetic Sampling
Motivated by SMOTE, He et al. (2009) introduce and garner widespread attention for the Adaptive Synthetic sampling (ADASYN) approach.
ADASYN creates minority class samples based on their density distributions. More synthetic data is generated for minority class samples that are more difficult to learn than for minority class samples that are easier to learn. It computes each minority instance’s K-nearest neighbours, then uses the class ratio of the minority and majority examples to produce new samples. Repeating this method adaptively adjusts the decision boundary to focus on difficult-to-learn instances.
Application with Python
The three oversampling strategies are demonstrated below. The code can be found on my github page.
|
|
RandomOverSampler Counter({1: 2590, 0: 300})
SMOTE Counter({1: 2590, 0: 300})
ADASYN Counter({0: 2604, 1: 2589})
The previous article Applying Under-Sampling Methods to Highly Imbalanced Data along with this article together can give you a comprehensive view of both the undersampling and oversampling techniques!
Conclusion
I hope this post has helped you better grasp this subject. Thank you very much for reading! 😄